Project Aims
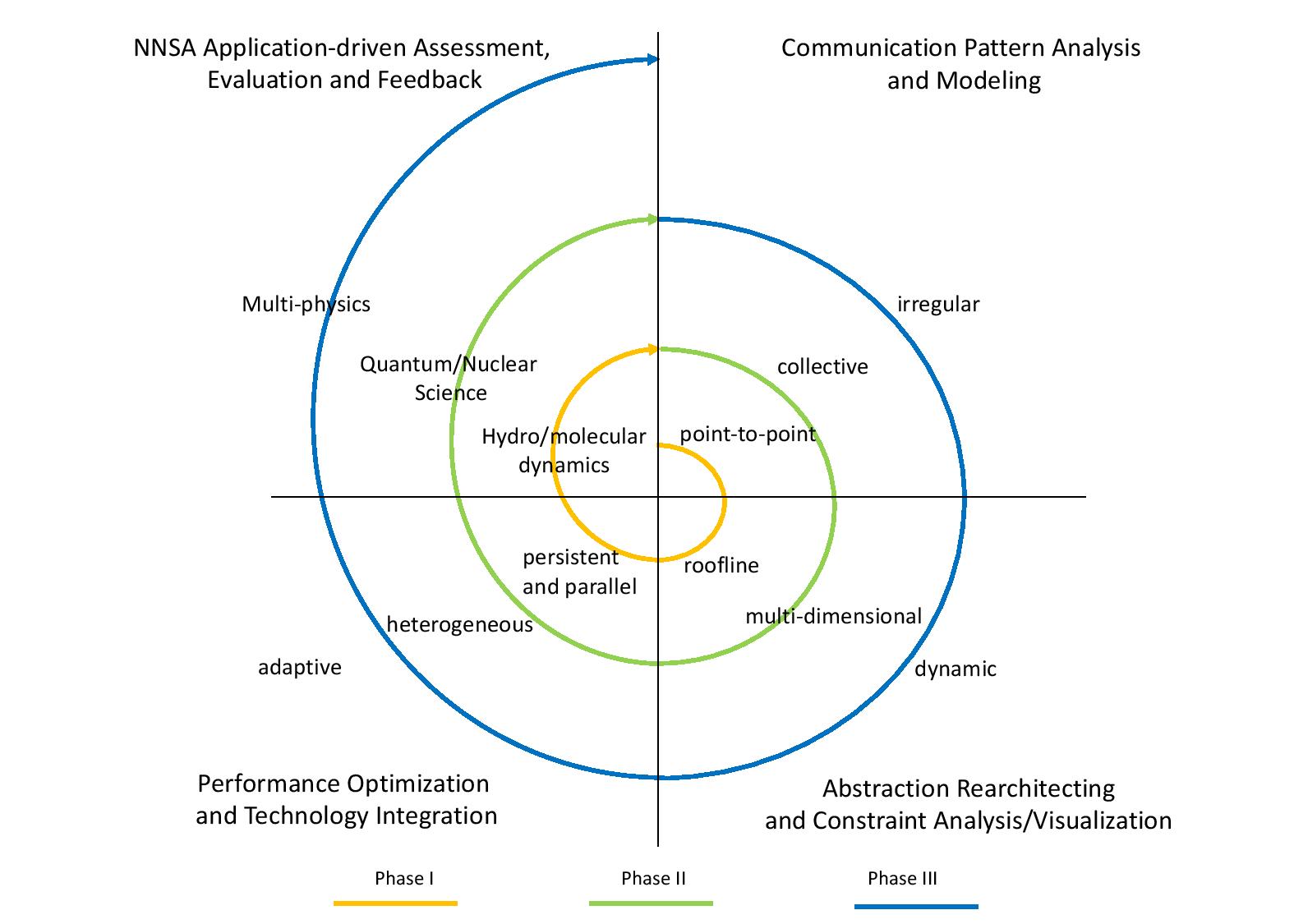
Assessment and Characterization of Application Communication Requirements
Understanding the current and future communication needs of modern HPC applications is a key research focus of the center, and results from this project inform and drive almost all other center research activities. As part of this effort, we are qualitatively and quantitively measuring the communication needs of a wide range of DOE applications in collaboration with National Lab partners.
Whenever possible, all data and analyses associated with this assessment is made publicly available through the center’s GitHub repositories. In addition, because many DOE applications have communication requirements not well-captured by public codes, we are also research the development of mini or proxy applications that better capture the communication needs of cutting-edge DOE science applications. The team’s preliminary work in this direction has examined the communication needs of a wide range of high-end applications.
Related Publications
- Laguna, I., Marshall, R., Mohror, K., Ruefenacht, M., Skjellum, A., & Sultana, N. (2019). A large-scale study of MPI usage in open-source HPC applications. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC '19). New York, NY: Association for Computing Machinery.
- Sultana, N., Rüfenacht, M., Skjellum, A., Bangalore, P., Laguna, I., & Mohror, K. (2020). Understanding the use of message passing interface in exascale proxy applications. Concurrency and Computation: Practice and Experience. https://doi.org/10.1002/cpe.5901
Communication Primitive Innovation
Designing new communication primitives for modern HPC applications, programming systems, and architectures is key center research direction. Current communication primitives were designed for single-threaded, non-accelerated systems, and optimized primarily for applications with regular communication patterns, and implemented for nodes with simple compute and memory architectures. Modern hardware architectures, programming systems, and scientific applications violate many if not all of these assumptions, so center researchers are working on new communication abstractions that accurately and efficiently map modern application communication needs to state-of-the-art hardware capabilities. The team’s preliminary work in this direction has focused on developing new point-to-point communication primitives for highly-threaded and accelerated applications, and these primitives have already been adopted into the most recent MPI standard.
Related Publications
- Grant, R., Skjellum, & A., Bangalore. (2015). Lightweight threading with MPI using Persistent Communications Semantics. Paper presented at 3rd Workshop on Exascale MPI, Austin, TX.
- Grant, R., Dosanjh, M., Levenhagen, M., Brightwell, R., & Skjellum, A. (2019). Finepoints: Partitioned Multithreaded MPI Communication. In Weiland M., Juckeland G., Trinitis C., Sadayappan P. (Eds.) High Performance Computing, (pp. 330-350). Cham, Switzerland: Springer.
Modeling MPI Application and Primitive Performance
To enable systematic optimization of HPC applications and their communication behavior, center personnel are researching a wide range of techniques for modelling application and communication primitive behavior on modern systems. High-fidelity performance models are a key component to effectively reason about, communicate, and optimize communication behavior in complex modern systems, and existing modeling approaches (e.g. LogGP, etc) are not sufficiently predictive of application performance. The team’s preliminary work has focused on modeling the coarse-grain performance of MPI applications as limited by communication primitives, and this work is being extended to provide high-resolution models of key communication primitives on modern hardware platforms.
Related Publications
- Mondragón, O., Bridges, P. G., Ferreira, K. B., Levy, S., & Widener, P. M. (2016). Understanding performance interference in next-generation HPC systems. Paper presented at 2016 ACM/IEEE Conference on Supercomputing (SC’16), Salt Lake City, UT.
- Bridges, P. G., Dosanjh, M. G. F., Grant, R., Skjellum, A., Farmer, S., & Brightwell, R. (2015). Preparing for exascale: Modeling MPI for many-core systems using fine-grain queues. In Proceedings of the 3rd Workshop on Exascale MPI. New York, NY: Association for Computing Machinery.
- Holmes, D. J., Morgan, B., Skjellum, A., Bangalore, P. V., & Sridharan, S. (2019). Planning for performance: Enhancing achievable performance for MPI through persistent collective operations. Parallel Computing, 81, 32-57. https://www.sciencedirect.com/science/article/abs/pii/S0167819118302412?via%3Dihub
Performance Characterization and Optimization of MPI Implementations
Researching and developing high-performance implementations of both current and novel HPC communication primitives is a key focus on center research to evaluate center research, to transition center research outcomes into practice, and to improve the quality, fidelity, and pace of computational research both general and at the DOE national laboratories. The complex of modern programming systems and computer architectures make creating high-performance implementations a significant engineering challenge, and center researchers leverage novel abstraction designs, performance models, careful experimental evaluation, and detailed knowledge of both software and hardware systems to do so effectively. The team’s preliminary work in this area has covered a wide range of MPI implementation optimizations, most recently related to threaded and one-sided communication primitives.
Related Publications
- Dosanjh, M. G. F., Schonbein, W., Grant, R., Bridges, P. G., Gazimirsaeed, S. M., & Afsahi, A. (2019). Fuzzy matching: Hardware accelerated MPI communication middleware. Proceedings of the 2019 19th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGRID), (pp. 210–220). https://ieeexplore.ieee.org/document/8752922
- Hjelm, N., Dosanjh, M. G. F., Grant, R., Groves, T., Bridges, P. G., & Arnold, D. (2018). Improving MPI multi-threaded RMA communication performance. Paper presented at Proceedings of the International Conference on Parallel Processing (ICPP 2018), Eugene, Oregon.
- Schonbein, W., Dosanjh, M. G. F., Grant, R. E., & Bridges, P. G. (2018). Measuring multithreaded message matching misery. In Aldinucci, M., Padovani, L., & Torquati, M. (Eds.), Proceedings of the 2018 European Conference on Parallel Processing (EuroPar 2018), (pp. 480–491). Cham, Swizerland: Springer.
- Dosanjh, M. G. F., Groves, T., Grant, R. E., Brightwell, R., & Bridges, P. G. (2016). RMA-MT: a benchmark suite for assessing MPI multi-threaded RMA performance. Paper presented at 16th IEEE/ACM International Symposium on Cluster, Cloud, and Grid Computing (CCGrid’16), Cartagena, Colombia.
- Xiong, Q., Bangalore, P. V., Skjellum, A., & Herbordt, M. C. (2018). MPI Derived Datatypes: Performance and Portability Issues. In EuroMPI’18: Proceedings of the 25th European MPI Users’ Group Meeting. New York, NY: Association for Computing Machinery.